Executive summary
For artificial intelligence to be trustworthy in a clinical setting, it must be able to show its work. The most important architectural pattern for achieving this in 2025 is Retrieval-Augmented Generation (RAG). RAG is a technique that forces a large language model (LLM) to ground its answers in an external, verifiable library of documents, which dramatically reduces factual "hallucinations" and enables the use of citations. This is a non-negotiable for any safety-critical application in healthcare (arXiv, MDPI).
The evidence for RAG in healthcare is growing. Studies have shown that RAG can significantly improve the accuracy of an LLM, with one pre-operative guidance study reporting an 11-percentage-point uplift in accuracy over a baseline GPT-4 model. This performance matched that of junior doctors on key tasks, but was delivered in a fraction of the time (arXiv). Real-world deployments, such as EBSCO's Dyna AI, now explicitly use RAG to provide clinicians with answers from vetted knowledgebases with transparent sourcing. For UK adoption, any RAG system must be built and governed in line with principles from the WHO and NIST, and align with the expectations of NHS assurance frameworks.
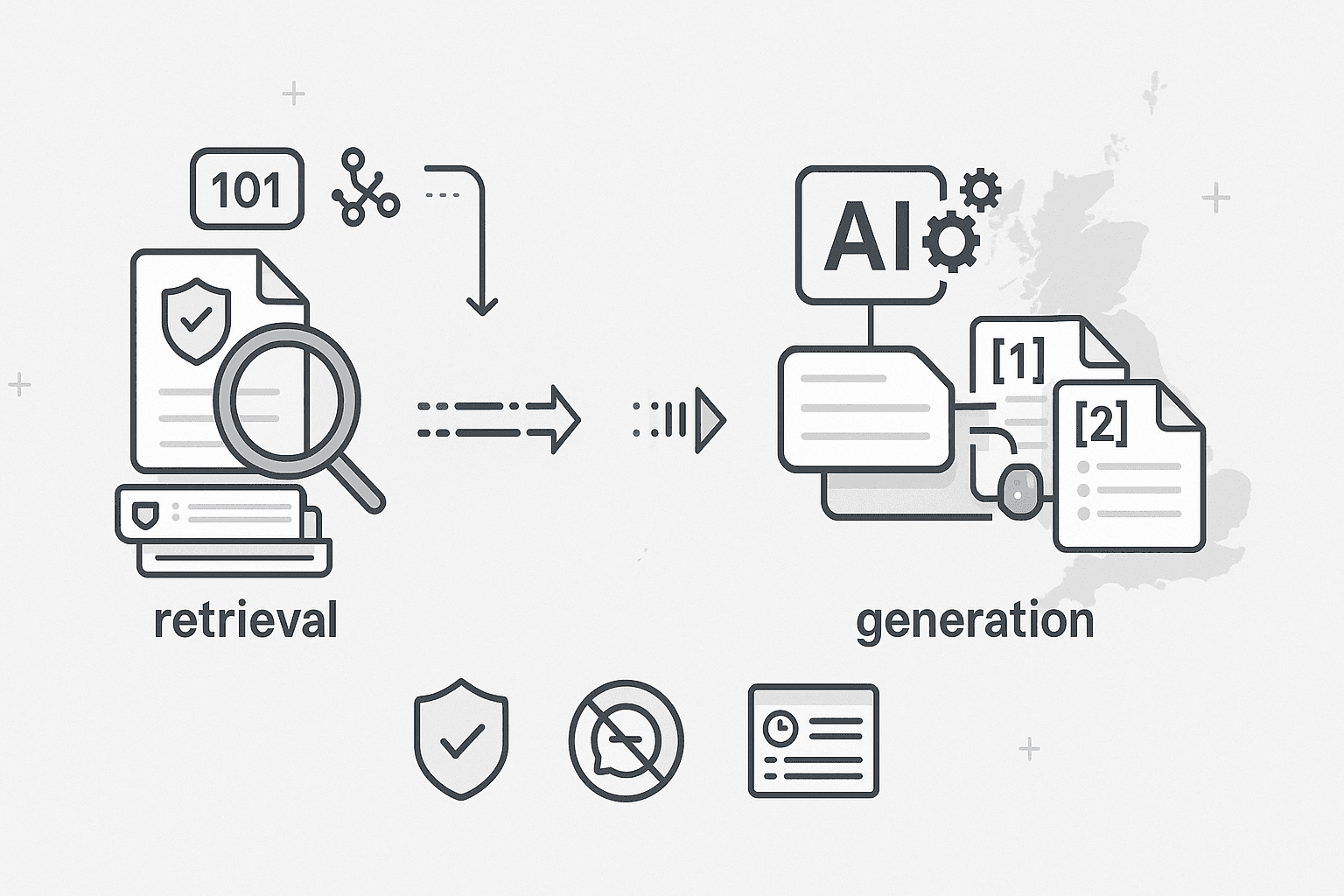
RAG 101: the idea in one graphic
The core problem with using general-purpose LLMs in medicine is that they are static—their knowledge is frozen in time—and they can confidently invent facts. RAG solves this. Instead of a single, closed-box model, RAG uses a two-part system:
- A Retriever: This is a powerful search engine that, when given a user's query, searches a specific, trusted library of documents to find the most relevant passages of text.
- A Generator: This is a standard LLM, but with a crucial instruction: it can only use the facts provided by the retriever to generate its final answer. It must also cite the sources it used.
This "retrieve → re-rank → generate with citations" loop is what separates a trustworthy clinical AI from a general-purpose chatbot (arXiv).
Clinical benefits you can bank on
- Fewer hallucinations, more provenance: Because the AI is forced to base its answers on retrieved documents, its ability to invent facts is dramatically reduced. Every claim can be traced back to a source document, allowing the user to click through and verify (PMC).
- Up-to-date guidance without full model retraining: When a clinical guideline changes, you don't need to retrain the entire multi-billion parameter AI model. You simply update the document in the knowledge library and the RAG system will start using the new information immediately (arXiv).
- Localisation to trusted, gated corpora: RAG allows for the creation of "walled-garden" systems that are restricted to a specific set of trusted documents. For UK/NHS practice, this means the AI can be limited to sources like NICE and SIGN guidelines, local hospital SOPs, and other nationally recognised guidance.
- Faster time-to-answer at the point of care: Studies have shown that a well-tuned RAG pipeline can synthesise information and provide an answer far faster than a human clinician performing a manual search (arXiv).
What the evidence says
- Narrative & systematic reviews: A growing body of literature concludes that RAG significantly improves factual consistency and traceability for medical question-answering and guideline interpretation tasks (PMC).
- Task-level studies:
- Pre-operative guidance: A key study found that when a baseline GPT-4 model was enhanced with RAG, its accuracy on providing pre-operative advice rose from ~80% to ~91%. This performance was non-inferior to that of junior clinicians, but the answers were generated significantly faster (arXiv).
- Public health content: A system called MEGA-RAG was specifically designed to mitigate hallucinations in the generation of public-health communications, demonstrating the architecture's value in ensuring factual accuracy (Frontiers).
Where RAG is already in production
- Clinical knowledge assistants: Dyna AI from EBSCO is a prime example. It explicitly uses a RAG architecture to provide natural-language answers from its curated DynaMed and DynaMedex databases, with a strong emphasis on transparent sourcing and showing the evidence.
- Healthcare bots & copilots: Major cloud platforms like Microsoft are now emphasising the importance of building compliant healthcare "copilots" that are grounded in curated content, with RAG being the core underlying technology.
Reference architecture for a safe healthcare RAG
- Gated corpus: The knowledge base must be restricted to authoritative, version-controlled sources.
- Hybrid retrieval: The best systems combine lexical search (like BM25) for finding exact terms with dense embedding search for understanding semantic meaning.
- Grounded generation: The LLM must be constrained to answer only from the retrieved snippets and must attach inline citations.
- Uncertainty & abstention: If the retriever finds no relevant evidence for a query, the system must be programmed to refuse to answer, rather than guessing.
- Audit & observability: Every prompt, retrieval, source, and final answer must be logged for quality assurance and incident review.
Evaluation: how to prove your RAG is trustworthy
- Retrieval metrics: Use technical measures like Recall@K and Precision@K to ensure the retriever is finding the right passages.
- Generation metrics: Use frameworks like RAGAs to measure faithfulness (does the answer stick to the retrieved evidence?) and answer correctness.
- Human review: For any safety-critical use case, a panel of clinicians must score the quality and safety of the answers, comparing them against both a baseline LLM and a human expert's response.
Governance & Risk (UK/Global Alignment)
- WHO LMM guidance: Emphasises transparency, provenance, and human oversight. RAG, with its citation and abstention features, is a direct technical implementation of these principles.
- NIST Generative AI Profile: Stresses the importance of documentation, data provenance, and continuous evaluation, all of which are supported by a well-logged RAG pipeline.
- Security: All platforms and plug-ins must be treated as part of the risk surface, with a focus on least-privilege access to the knowledge indices.
Buyer’s checklist: choosing (or building) a healthcare-grade RAG
- Sources: Is the knowledge corpus gated to trusted, version-controlled guidance?
- Retrieval: Does the system use a hybrid search model with re-ranking?
- Answers: Are inline citations, quote-back snippets, and uncertainty statements provided by default?
- Evaluation: Can the vendor provide published retrieval and faithfulness metrics?
- Ops & compliance: Are there full audit logs and a clear update cadence? Are there DPIA and DTAC-style artefacts available?
Implementation playbooks
- Clinician Q&A: Start with a narrow, high-value corpus of national guidelines. Measure faithfulness and user-verified correctness weekly.
- Patient-facing info (e.g., pre-op consent): Build a RAG bot over local patient leaflets and national guidance. Pre-register your outcomes on patient comprehension and safety-netting.
- Operational copilots (e.g., for EMR manuals): Index your internal SOPs and track the deflection rate from your IT service desk.
FAQs
- Does RAG really reduce hallucinations?
- Yes. Multiple peer-reviewed studies and reviews have shown that RAG significantly improves factual consistency and traceability compared to using an LLM alone, provided the retrieval is strong and the answers are constrained to the evidence.
- How much of an accuracy gain can I expect?
- This is highly task-dependent. However, an exemplar study on pre-operative guidance reported an approximately 11-percentage-point uplift in accuracy over a baseline GPT-4 model, achieving non-inferiority to junior clinicians.
- Is RAG enough for clinical safety?
- No. It is a powerful architectural pattern, but it must be paired with robust governance (as per WHO/NIST guidance), clear refusal policies, and non-negotiable human oversight for all clinical decisions.
- Who’s using RAG in healthcare today?
- Major clinical knowledge assistants like EBSCO's Dyna AI explicitly use RAG to ground their answers in vetted databases with clear citations.